
El fenómeno del avance de la inteligencia artificial generativa despierta gran interés. En Estados Unidos, son las grandes empresas tecnológicas y emergentes como OpenAI las que han tomado la delantera. En China, el desarrollo también avanza, impulsado no solo por intereses tecnológicos, sino también con objetivos sociales y médicos. Ahora, Latinoamérica ha decidido dar un paso adelante creando su propia versión de ChatGPT.
Este nuevo modelo se llamará Latam-GPT y el incentivo para su desarrollo tiene una curiosa raíz: la insatisfacción de un centro chileno con una respuesta otorgada por ChatGPT sobre la cultura latinoamericana.
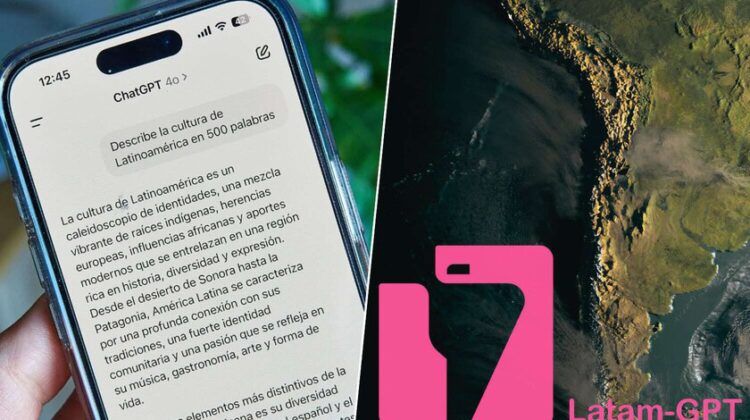
La pregunta. Investigadores del Centro Nacional de Inteligencia Artificial (CENIA) de Chile solicitaron a ChatGPT: “Describe la cultura latinoamericana en 500 caracteres”. La respuesta fue la siguiente:
«La cultura latinoamericana es una amalgama vibrante de raíces indígenas, influencias africanas y herencia europea. Se caracteriza por su rica diversidad en música, danza y gastronomía, reflejada en festivales como el Carnaval y la Feria de las Flores. Su arte, desde el muralismo hasta la literatura, muestra una profunda conexión con la historia y la identidad local. La calidez, el sentido de comunidad y la celebración de la vida son pilares que enriquecen esta dinámica y diversa cultura”.

He repetido la consulta y, aunque la respuesta varía, sigue centrada en los mismos aspectos: la mezcla de herencias indígenas, africanas y europeas, el entusiasmo por la música y la danza, la vibrante gastronomía y tradiciones como el carnaval que configuran un mosaico cultural colorido.
Latam-GPT. Esta respuesta no convenció a los investigadores del CENIA, quienes consideraron que el modelo, a pesar de su alta calidad, debería captar mejor el contexto latinoamericano. La respuesta generalista no reflejaba las particularidades de cada país.
Latam-GPT será la alternativa para la región. Será un modelo de lenguaje creado por y para América Latina y el Caribe, con el objetivo de abordar las dificultades de los modelos actuales al interpretar modismos y expresiones culturales propias del contexto local. Álvaro Soto, director del CENIA, señala que los modelos estadounidenses ofrecen respuestas limitadas debido al poco volumen de datos latinoamericanos en su entrenamiento.
“No buscamos competir con OpenAI o uno de los gigantes. Queremos un modelo propio de Latinoamérica y el Caribe, con los requisitos y desafíos culturales que eso implica” – CENIA
Objetivos. Hay tres principales. Primero, mejorar la capacidad del modelo para captar el contexto cultural de cada país latinoamericano. Segundo, asegurar que el modelo sea abierto y público, permitiendo a los desarrolladores locales adaptarlo a necesidades específicas en sectores como la educación, política, economía o medio ambiente.
El tercer objetivo es crucial para lograr la independencia tecnológica que la región busca. México, por ejemplo, ha planteado el Plan México, con proyectos que buscan fortalecer la soberanía en distintos ámbitos, incluidas las tecnologías, ya sea mediante la fabricación de semiconductores o vehículos eléctricos.

Financiación. Con Latam-GPT, también se busca fomentar la innovación tecnológica regional, pero eso requiere financiación. Chile lidera el proyecto, con el apoyo de México, Argentina, Colombia, Perú, Uruguay, Costa Rica y Ecuador, además de instituciones españolas y estadounidenses.
El proyecto está financiado por asociaciones e instituciones académicas de estos países, con respaldo gubernamental para avanzar en el desarrollo de esta inteligencia artificial.
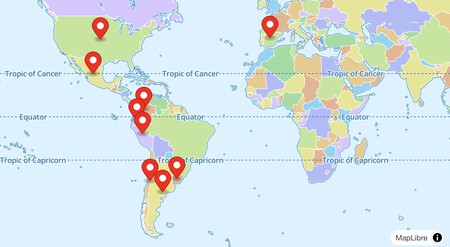
Varios países están inmersos en Latam-GPT
Recursos. La Universidad de Tarapacá, en Chile, proporcionará infraestructura para el entrenamiento de Latam-GPT utilizando un superordenador con datos de bibliotecas públicas y privadas, en un proceso que se estima durará 40 días, con la intención de que esté disponible para el verano de 2025. La inversión en infraestructura será de aproximadamente 10 millones de dólares.
Un posible inconveniente es el consumo energético del centro de entrenamiento. En España, la construcción de centros de datos genera controversia por el alto consumo de agua y energía; sin embargo, el CENIA sostiene que el consumo inicial será de 135 kWh.
La Universidad de Tarapacá está ubicada en Arica, una región con abundante energía renovable, y planean utilizarla para alimentar el proyecto. Además, aseguran que el sistema de refrigeración no consumirá agua debido a la disponibilidad de energía barata y abundante. Las emisiones de CO₂ asociadas al entrenamiento se estiman en 0,96 toneladas.
¿Necesario? Este emprendimiento podría ser más ecológico que otros modelos, pero enfrenta desafíos, incluyendo la protección de datos durante el entrenamiento. Los investigadores aseguran que utilizarán políticas de transparencia y fuentes abiertas que respeten los derechos de autor mientras anonimizan los datos personales.
Sin embargo, surge la pregunta de la finalidad de todo esto. Ulises Mejías, profesor de la Universidad Estatal de Nueva York y de origen mexicano, expresó a BBC Mundo sus dudas: aunque el proyecto es ambicioso y bien financiado, no se siente seguro sobre su capacidad para diferenciarse realmente de los modelos de EE. UU. y China.
«¿Busca el proyecto Latam-GPT ofrecer una nueva perspectiva sobre el propósito de la inteligencia artificial generativa, o simplemente reproduce la idea de que la IA sirve para reducir costos laborales y maximizar beneficios?”, reflexiona Mejías.
NVIDIA siempre gana. Independientemente de las dudas, el desarrollo de Latam-GPT avanza, y se espera que en pocos meses podamos ver los resultados de esta iniciativa. A pesar de los intentos de independizarse de tecnologías extranjeras, NVIDIA sigue siendo un actor clave con tecnología esencial para este proyecto.
El centro de datos contará con 12 nodos, cada uno con ocho GPU NVIDIA H200, necesarias para entrenar el modelo con 50 billones de parámetros, similar a GPT-3.5. Se prevé que esta primera versión se fortalecerá con mejoras continuas a medida que más instituciones se sumen y se integren nuevos datos.
Estaremos atentos al progreso de Latam-GPT. No solo su lanzamiento, sino su evolución determinará el éxito o fracaso del modelo.
Deja una respuesta