

En la escena actual de la inteligencia artificial, un nombre destaca: Gemini 2.5 Pro. Este modelo es considerado el más avanzado, al menos en el presente, según lo indica el ranking de Chatbot Arena. Esta plataforma somete a los modelos de IA a varios benchmarks para evaluar su capacidad global.
De acuerdo con estas evaluaciones, el recién lanzado Gemini 2.5 Pro Experimental supera a modelos famosos como GPT-4o, Grok 3 y GPT-4.5, e incluso está por delante de DeepSeek R1, a menudo elogiado aunque se ubica en la séptima posición.
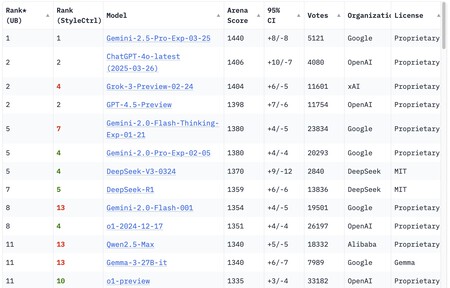
Actualmente, Chatbot Arena clasifica a Gemini Pro 2.5 Experimental como el modelo de IA más avanzado. Sin embargo, esto podría cambiar pronto.
Google también ha celebrado el poder de este nuevo modelo, publicando comparativas en las que Gemini 2.5 Pro supera a sus rivales en pruebas de gran renombre dentro del sector.
Ejemplos de estas pruebas incluyen el Humanity’s Last Exam (conocimientos generales y razonamiento), GPQA diamond (ciencia), AIME 2025 (matemáticas), LiveCodeBench v5 y SWE-bench verified (programación), o MMMU (razonamiento visual).
Estos benchmarks intentan evaluar habilidades específicas de los modelos pero no logran responder la pregunta crucial:
¿Puede la IA alcanzar la inteligencia humana?
Este es un debate complejo, ya que la inteligencia misma es difícil de definir. Existen múltiples tipos de inteligencia y evaluarlas en humanos ya es complicado, por lo que comparar la inteligencia artificial con la humana presenta mayores retos.
Algunos expertos cuestionan si los laboratorios de IA no están manipulando los benchmarks.
Algunos, como Dean Valentine de ZeroPath, opinan que el progreso mostrado por los modelos de IA puede ser engañoso. Aunque con Claude 3.5 Sonnet observaron una mejora significativa, las versiones posteriores les resultaron menos impresionantes.
Valentine sugiere que las empresas podrían estar enfocándose en brillar en los benchmarks más populares y en «parecer inteligentes» en interacciones con humanos, poniendo en duda la correspondencia entre las mejoras observadas en estos benchmarks y sus beneficios prácticos.
FrontierMath: El Desafío de Resolución de Problemas Complejos
Para abordar estas inquietudes, existen proyectos como ARC-AGI 2, que propone pruebas que, aunque fáciles para humanos, son complejas para la IA, derivados de la paradoja de Moravec.

Jaime Sevilla, CEO de Epoch AI.
Estas evaluaciones examinan la capacidad de generalización y razonamiento abstracto mediante puzzles visuales, proporcionando así una medida del avance de los modelos de IA.
Otra prueba reciente de gran interés es FrontierMath. Esta fue desarrollada por EpochAI y presenta unos 300 problemas matemáticos de variada dificultad.
Creados por un equipo diverso de matemáticos, incluido Terence Tao, estos problemas son desafiantes, con al menos un 25% categorizados como extremadamente complejos, resolvibles solo por los expertos más calificados y en un tiempo considerable.

Además, estos problemas son inéditos y no forman parte de los datos de entrenamiento de los modelos actuales, requiriendo que las máquinas demuestren una capacidad de resolución única.
En una conversación con Jaime Sevilla (@Jsevillamol), CEO de EpochAI, se revelaron sus perspectivas sobre la medición de la capacidad de un modelo de IA.
Según Sevilla, «es crucial tener un método para medir el progreso de la IA. La interacción ofrece perspectiva, pero no proporciona una evaluación rigurosa sobre los límites y especialidades del modelo».

Esto implica la necesidad de pruebas estandarizadas para comprender mejor las capacidades de la IA. A su juicio, ARC-AGI refleja bien esta idea al ser fácil para humanos pero no para la IA.
Los modelos avanzan en ARC-AGI, pero con FrontierMath buscan verificar si la IA puede abordar problemas realmente difíciles, ya que los anteriores benchmarks eran demasiado fáciles y rápidamente superados.
Un ejemplo es el modelo o3-mini de OpenAI, que resuelve un 10% de FrontierMath. Este logro, aunque parezca modesto, supera los resultados de matemáticos de élite.
«Superar benchmarks no implica ser un experto humano. Es necesario ajustarlos a escenarios más variados para medir los límites de la IA», explica.
Sevilla resalta la importancia de medir la capacidad de la IA en tareas autónomas y remotas, con benchmarks como OSWorld buscando evaluar la efectividad de estos agentes, aunque aún en etapas básicas.

El ciclo comienza con benchmarks que no ofrecen resultados, pero luego, tras mejoras predecibles, los modelos logran saturarlos, lo que demuestra el avance técnico.
En cuanto al debate del escalado, Sevilla defiende la inversión en recursos, pues argumenta que el uso de más cómputo sigue proporcionando mejoras, pese a que en algunos aspectos el progreso sea menos evidente.
«No hay pruebas suficientes de que el escalado haya alcanzado su límite. Más cómputo sigue traduciéndose en mejores resultados».
«Históricamente, más recursos han impulsado mejoras notables», subraya, indicando que aunque el progreso en áreas sin razonamiento ha sido decepcionante, el razonamiento sí ha mostrado funcionar bien.
Sevilla concluye que «no hay pruebas suficientes de que el escalado haya agotado su potencial. Más cómputo aún produce mejores resultados».
«La IA Opera de Manera Diferente a Nosotros»
Para Sevilla, «es claro que la IA no opera como los humanos. Supera nuestras capacidades en áreas como medicina, biología y ha mostrado progresos significativos en matemáticas y programación». No obstante, menciona que en tareas como jugar a Pokémon, la IA no destaca.

El rendimiento de la IA en problemas matemáticos avanzados sigue siendo bajo: o3-mini, el que mejor lo hace, solo resuelve el 11% de esos problemas. Fuente: Epoch AI.
Sevilla sugiere que los avances en IA se producirán sobre todo en campos donde los humanos no han evolucionado, como matemáticas e ingeniería, más que en áreas como robótica.
En un estudio reciente de Metr se observa cómo la IA progresa de manera previsible en la ejecución de tareas, y se espera que en menos de diez años, los agentes de IA realicen gran parte de las tareas de software hoy llevadas a cabo por humanos.
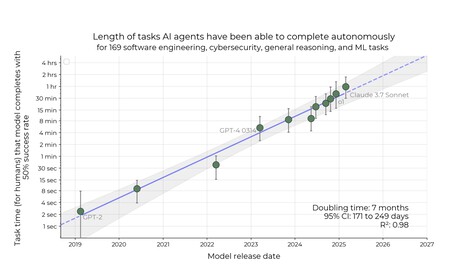
Según el estudio, la capacidad de la IA para completar tareas ha mejorado de manera constante, aproximadamente duplicándose cada 7 meses en los últimos seis años.
La predicción es que en menos de una década, los agentes de IA podrán encargarse de tareas que actualmente requieren días o semanas de esfuerzo humano.
«La IA no solo replica lo aprendido, sino que lo combina innovadoramente».
Sevilla también aborda la crítica de que la IA no genera nuevo conocimiento, sino que simplemente reproduce lo aprendido. Para él, la inteligencia humana hace lo mismo, y FrontierMath demuestra que la IA combina los datos de manera innovadora.
Finalmente, Sevilla se muestra optimista sobre el futuro de la IA. Observa una tendencia de aumento de recursos dedicados que sugiere un avance significativo similar al observado entre GPT-2 y GPT-4.
Concluye que «para finales de la década, veremos un salto significativo» entre lo que tenemos actualmente y lo que está por venir, con credibilidad en el potencial de estos desarrollos asombrosos. Benchmarks como FrontierMath serán testigos de este avance.
Deja una respuesta