

El debut de Apple Intelligence no ha sido el que muchos esperaban, dejando aún un amplio margen de mejora tanto en inglés como en español. A pesar de su presentación como una fuerte carta de venta, su recepción ha sido modesta. Las primeras reacciones han sido diversas, sin alcanzar aún un gran entusiasmo.
Desde Cupertino, la empresa se está moviendo para fortalecer uno de los proyectos de software más ambiciosos en su historia reciente. Destacan dos líneas de acción: la anunciada reestructuración del equipo de Siri, cuya actualización se ha pospuesto hasta 2026, y el desarrollo de técnicas innovadoras para mejorar sus modelos de lenguaje, sin comprometer su compromiso con la privacidad.
Más allá de los datos sintéticos
Apple ha estado utilizando datos sintéticos y etiquetados por humanos para entrenar sus modelos; sin embargo, esta metodología tiene sus limitaciones al no reflejar siempre el mundo real, afectando el desempeño de sus productos de IA. Ante esto, la compañía bajo la dirección de Tim Cook se ha embarcado en una nueva estrategia que combina datos sintéticos con señales anónimas de dispositivos de usuarios.
Según un artículo reciente, el proceso comienza con mensajes sintéticos creados por Apple, como un correo ficticio que simula correos reales. Un ejemplo podría ser: “¿Te gustaría jugar al tenis mañana a las 11:30?”. A partir de estos, se generan diversas variantes ajustando elementos como el deporte, la hora o el tono, probando diferentes estructuras.
Estas frases son enviadas a dispositivos cuyos usuarios han optado por compartir analítica con Apple. En estos dispositivos, cada iPhone, iPad o Mac transforma algunos correos reales en embeddings locales, representaciones matemáticas que califican cada mensaje según su tema, estilo y longitud. Es esencial que estos correos no salgan del dispositivo.
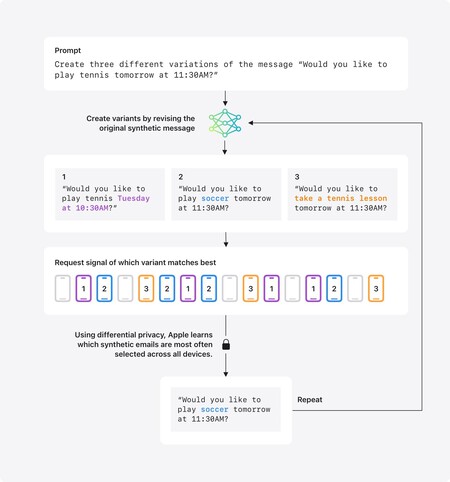
El sistema compara las embeddings sintéticas de Apple con las embeddings locales para determinar similitudes. Esta comparación se traduce en una señal anónima, indicando cuál versión se asemeja más al uso real, que se envía a Apple sin revelar el correo original o la embedding del usuario. Así, Apple busca aprender qué variantes sintéticas reflejan con más precisión el lenguaje real, sin acceder a contenido privado.
Este método aspira a mejorar funciones de Apple Intelligence, tales como resúmenes de correos electrónicos y herramientas de redacción.
La técnica se asienta sobre las mismas bases de privacidad diferencial usadas en funciones previas como Genmoji. En Genmoji, Apple recoge señales anónimas sobre prompts populares para optimizar los resultados sin registrar las solicitudes exactas de los usuarios.

La idea es simple pero efectiva: perfeccionar los modelos de lenguaje al mismo tiempo que se protege la privacidad de los usuarios, una bandera que la empresa ha alzado durante años.
Este nuevo método se implementará en las próximas versiones beta de iOS 18.5, iPadOS 18.5 y macOS 15.5. Cabe mencionar que solo participarán aquellos usuarios que hayan activado el compartir analítica en los ajustes de privacidad. Si prefieres no participar en este sistema, puedes desactivarlo en cualquier momento. Simplemente dirígete a Ajustes > Privacidad y seguridad > Análisis y mejoras y desactiva la opción de “Compartir análisis del iPhone”.
Imágenes | Apple | appshunter
Deja una respuesta