

Las inteligencias artificiales operan sin comprender realmente el contenido de sus acciones. A pesar de que sus respuestas suelen ser coherentes, los errores parecen inevitables y, hasta ahora, no entendemos cómo operan internamente. Sin embargo, este panorama podría cambiar pronto.
Desentrañando el misterio. Los desarrolladores de Anthropic, conocidos por el chatbot Claude, han hecho un avance significativo que podría ofrecer una nueva perspectiva sobre el funcionamiento de los modelos de lenguaje. Estos sistemas actúan como enigmas: conocemos sus entradas y resultados, pero el proceso interno sigue siendo un misterio. Su nuevo descubrimiento promete arrojar luz sobre esta «caja negra».

La relevancia de entender el pensamiento de la IA. La opacidad de los modelos de IA plantea retos cruciales. Dificulta prever errores y sus causas. Descifrar su funcionamiento interno ayudaría a entender y corregir respuestas incorrectas, optimizando así el rendimiento de estos sistemas.
Mayor seguridad y confiabilidad. Comprender las razones detrás de las decisiones de la IA sería esencial para aumentar nuestra confianza en estos sistemas. Esto ofrecería mayores garantías en términos de privacidad y seguridad de los datos, eliminando barreras para su adopción empresarial.
Un vistazo a modelos de razonamiento. Modelos como o1 y DeepSeek R1 pretenden desvelar el proceso de razonamiento mostrando tareas completadas («búsqueda en la web», «análisis de información», etc.). Sin embargo, esta «secuencia de pensamiento» no captura completamente cómo procesan nuestras solicitudes.
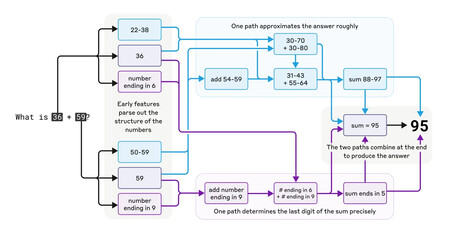
¿Cómo maneja Claude un cálculo como 36+59? Aunque el proceso no es completamente claro, Anthropic está empezando a descifrarlo. Fuente: Anthropic.
Desentrañando la mente de la IA. Los ingenieros de Anthropic han diseñado una herramienta que aborda la complejidad interna de estos sistemas, similar a un escáner cerebral que identifica qué partes del cerebro participan en funciones cognitivas específicas.
Perspectivas a largo plazo. Aunque modelos como Claude predicen la siguiente palabra en una oración, ciertas tareas sugieren que Claude desarrolla un tipo de planificación a largo plazo. Por ejemplo, en la creación de poemas, organiza palabras acordes al tema antes de estructurar los versos.
Pensar en un idioma, traducir a muchos. Aunque Claude soporta varios idiomas, los expertos de Anthropic sostienen que no «piensa» directamente en ellos. Utiliza conceptos universales entre lenguas, aparentemente razonando en una única lengua y luego traduciendo al idioma requerido.
Cuando los modelos engañan. La investigación ha descubierto que los modelos pueden falsear sus acciones, fingiendo procesos como el cálculo sin realmente realizarlos. Josh Batson, desarrollador de Claude, destaca cómo las técnicas de interpretabilidad no siempre revelan la veracidad de sus reclamos.
El método de descifrado de Anthropic. Basado en el Cross-Layer Transcoder (CLT), este método analiza conjuntos de características interpretables en lugar de neuronas individuales. Esto facilita la identificación de «circuitos» neuronales que colaboran en diversas funciones.
Un prometedor inicio. OpenAI intentó previamente entender cómo piensan sus modelos IA sin gran éxito. Aunque el método de Anthropic tiene sus limitaciones, la empresa espera que en cuestión de años se comprenda más sobre el pensamiento de estos modelos que sobre el humano, según Batson.
Deja una respuesta