

El modelo o3 de OpenAI ha demostrado ser increíblemente avanzado, superando las pruebas y benchmarks existentes en programación, matemáticas y razonamiento como ningún otro modelo de IA lo ha hecho antes. Este avance ha puesto de manifiesto la necesidad de idear nuevas pruebas que realmente pongan a prueba la capacidad de estas inteligencias artificiales. Actualmente, los expertos están trabajando en ello.
Los exámenes tradicionales ya no funcionan. A principios de 2023, ChatGPT ya lograba aprobar exámenes de derecho y MBA, aunque con notas justas. Según Time, dos años después, el progreso de los modelos es tan significativo que tanto los exámenes diseñados para humanos como los benchmarks existentes se han quedado obsoletos. Esta situación era previsible.

Un progreso acelerado. En 2010, la profesora de Stanford Fei-Fei Li desarrolló un benchmark conocido como ImageNet Large Scale Visual Recognition Challenge. Cinco años después, un sistema de visión artificial superó este desafío. En 2017, DeepMind con AlphaGo derrotó al mejor jugador de Go del mundo, rememorando el hito de DeepBlue. Aunque se creía que estos retos serían insuperables por las máquinas en mucho tiempo, el avance de la IA ha sido vertiginoso y los modelos actuales están progresando aún más rápidamente.
FrontierMath. La ONG de investigación Epoch AI ha creado un nuevo conjunto de pruebas matemáticas llamado FrontierMath. Hasta hace poco, modelos como GPT-4 o Claude apenas alcanzaban un 2% en estas pruebas, lo que indicaba un gran margen de mejora. El debut de o3 ha transformado el escenario al alcanzar un 25,2% de rendimiento, una cifra que sorprendió al equipo de Epoch AI, como indicó su director Jaime Sevilla.
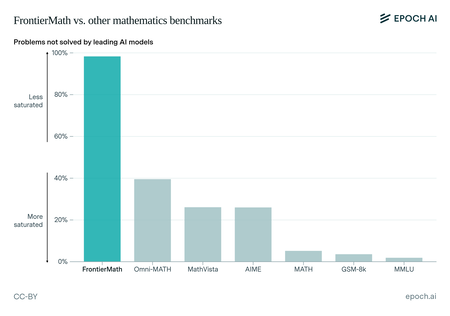
Mientras los modelos de IA superaban con facilidad otros benchmarks matemáticos, FrontierMath ha planteado un nuevo desafío. Pero ya o3 ha logrado una impresionante puntuación del 25,2% (no visible en este gráfico, donde apenas llegaban al 2%). Fuente: Epoch AI.
Pruebas más rigurosas. FrontierMath consta de alrededor de 300 problemas matemáticos de diversos niveles de dificultad, ideados por un equipo de más de 60 matemáticos, entre ellos Terence Tao, ganador de la medalla Fields. Algunos son más sencillos, pero el 25% son especialmente complejos, resolubles solo por expertos y que podrían llevar días solucionar.
Humanity’s Last Exam. Otra prueba reciente es Humanity’s Last Exam, que cuenta con entre 20 y 50 veces más preguntas que FrontierMath, abarcando muchas disciplinas. Las preguntas han sido colectadas de la comunidad académica, y para ser incluida, una pregunta debe no haber sido respondida correctamente por los modelos actuales. Su lanzamiento está previsto para principios de 2025.
La paradoja de Moravec. Los retos más interesantes son aquellos que exploran la paradoja de Moravec, donde las tareas fáciles para los humanos resultan difíciles para las máquinas.
ARC-AGI. Este es el enfoque del benchmark ARC-AGI, creado por François Chollet en 2019. En su última versión, plantea pruebas donde la mayoría de modelos fallan. O1 mini solo logró un 7,8%, pero o3 ha sorprendido al alcanzar un 87,5% en su modo avanzado (muy costoso) y un 75,7% en el modo de bajo consumo, un logro excepcional. Naturalmente, los creadores de ARC-AGI ya están trabajando en un nuevo y más riguroso benchmark que esperan tome mucho tiempo superar.
Imagen | Crymedy7 con Midjourney
Deja una respuesta